

feature pyramid network with yolov3
- views: 0
- author: ha4219
- January 20, 2022
- 16 min read
Feature Pyramid Networks for Object Detection
Abstract
Feature pyramids are a basic component in recognitionsystems for detecting objects at different scales. But recentdeep learning object detectors have avoided pyramid representations, in part because they are compute and memoryintensive. In this paper, we exploit the inherent multi-scale,pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost. A topdown architecture with lateral connections is developed forbuilding high-level semantic feature maps at all scales. Thisarchitecture, called a Feature Pyramid Network (FPN),shows significant improvement as a generic feature extractor in several applications. Using FPN in a basic FasterR-CNN system, our method achieves state-of-the-art singlemodel results on the COCO detection benchmark withoutbells and whistles, surpassing all existing single-model entries including those from the COCO 2016 challenge winners. In addition, our method can run at 6 FPS on a GPUand thus is a practical and accurate solution to multi-scaleobject detection. Code will be made publicly available.
- FPN은 여러가지 scale을 가진 객체탐지에 기본적인 component이다. 하지만 최근 다른 연구에서는 복잡하고 메모리 집중적이기 때문에 pyramid representations 피한다. 본 논문에서, 한계 추가 비용으로 feature pyramid를 구성하기 위해 고유의 multi-scale, 즉 pyramidal hierarchy of deep convolutional networks(convolutional network의 피라미드 계층)을 활용한다. All scale에 high-level feature maps에 대한 top-down 구조는 개발됐다. FPN은 몇가지 application의 generic feature extractor에 중요한 성장을 보여준다. FPN을 사용한 Faster-RCNN은 without bells and whistles, COCO detection benchmark에서 최첨단? 단일 모델 결과를 달성하여 COCO 2016 challenge 우승자를 포함한 모든 기존 단일 모델 항목을 능가한다. 추가로 우리 모델은 GPU 환경에서 6 FPS를 갖는다. 따라서 multi-scale 객체탐지에 실용적이고 정확한 해결책이다. code는 곧 공식적으로 이용 가능하다.
1. Introduction
Recognizing objects at vastly different scales is a fundamental challenge in computer vision. Feature pyramids built upon image pyramids (for short we call these featurized image pyramids) form the basis of a standard solution [1] (Fig. 1(a)). These pyramids are scale-invariant in the sense that an object’s scale change is offset by shifting itslevel in the pyramid. Intuitively, this property enables a model to detect objects across a large range of scales by scanning the model over both positions and pyramid levels.Featurized image pyramids were heavily used in the era of hand-engineered features [5, 25]. They were so critical that object detectors like DPM [7] required dense scale sampling to achieve good results (e.g., 10 scales per octave). For recognition tasks, engineered features have largely been replaced with features computed by deep convolutional networks (ConvNets) [19, 20]. Aside from being capable of representing higher-level semantics, ConvNets are also more robust to variance in scale and thus facilitate recognition from features computed on a single input scale [15, 11, 29] (Fig. 1(b)). But even with this robustness, pyramids are still needed to get the most accurate results. All recent top entries in the ImageNet [33] and COCO [21] detection challenges use multi-scale testing on featurized image pyramids (e.g., [16, 35]). The principle advantage of featurizing each level of an image pyramid is that it produces a multi-scale feature representation in which all levels are semantically strong, including the high-resolution levels.Nevertheless, featurizing each level of an image pyramid has obvious limitations. Inference time increases considerably (e.g., by four times [11]), making this approachimpractical for real applications. Moreover, training deep
- 매우 다른 sacles에 객체를 인식하는 것은 CV에 기초적인 과제이다. image pyramids에서 형성된 Feature pyramids는 기본적인 해결책의 근간을 형성한다. pyramids는 물체의 스케일 변화가 다음 값을 이동함으로써 상쇄된다는 점에서 scale-불변이다. 직관적으로, this property를 사용하면 모델이 위치 및 피라미드 레벨 모두에서 모델을 스캔하여 광범위한 축척에 걸쳐 객체를 탐지할 수 있습니다.
- Featurized image pyramids는 hand-engineered features에서 많이 사용된다. DPM과 같은 object detectors가 좋은 결과를 내기 위해 dense scale sampling이 필요한 것은 치명적이다. 인식 과제에서, engineered된 feature들은 deep ConvNets으로 계산된 features으로 바뀌었다. 더 높은 semantics를 나타낼 뿐만 아니라, ConvNets scale 변화에 강력하다. 따라서 single input scale에서 계산된 features로 인식을 용이하게 한다. 강건하지만 pyramids는 여전히 가장 좋은 정확도 결과를 필요로 한다. 최근 유명 대회에 참가하는 모델들은 featurized image pyramids에 multi-scale testing을 사용한다. 각 level에 image pyramid를 featurizing의 주요 이점은 고해상도를 포함한 모든 level에서 semantically strong한 multi-scale feature 를 제공한다.
- 그럼에도 불구하고 명백한 한계가 존재한다. 시간이 상당히 증가하고 실제 app에서 비실용적일 것이라고 예측된다. 게다가 end-to-end networks에 올리는 것은 메모리적으로 실현 불가능하고 image pyramid는 오직 test time에 사용되기에 train과 test-time 추론 사이에 모순이 발생한다. 이러한 이유로 Fast, Faster R-CNN은 featurized image pyramids를 기본 세팅에 사용하지 않기로 선택했다.
- 하지만 image pyrmaid는 오직 multi-scale feature representation을 계산하는 것만 있는게 아니다. deep ConvNet은 각 layer마다 feature hierarchy를 계산하고 feature 계층을 subsampling은 고유한 multi-scale과 pyramidal shape를 갖고 있다. 이러한 feature hierarchy는 각기 다른 해상도의 feature map을 제공하지만 깊이에 따라 야기되는 큰 semantic gaps을 보여준다. 높은 해상도 maps은 인식 능력에 안좋은 낮은 feature를 갖고있다.
- SSD는 ConvNet의 마치 featurized image pyramid처럼 pyramidal feature hierarchy를 처음 사용한 시도 중 하나이다. 이상적으로 SSD-style pyramid는 다른 여러 이전에 통과된 layer로 부터 multi-scale feature maps을 재사용해서 cost가 적다. 그러나 low-level feature을 사용하지 않으려면 SSD는 이미 계산된 hierarchy를 다시 사용하고 대신 새로운 layer를 추가하면서 network의 상위 계층으로부터 pyramid를 구축한다. 따라서 고해상도 계층맵을 사용할 기회를 잃는다. 고해상도 맵은 작은 객체를 탐지할 때 중요하다.
- 이 논문의 목표는 모든 scale에 강력한 ConvNet's feature hierarchy를 만들어서 pyramid shape에 영향을 주는 것이다. 목표를 달성하려면 낮은 해상도와 높은 해상도의 semantically 한 강한 features 그리고 top-down pathway와 lateral connections을 통과하고 semantically하고 약한 features들 구조에 달려있다.
Ref
정말 많이 보고 배워서 참고합니다. 또한 영상 내용을 시간을 바탕으로 제가 새로 재구성했습니다.
- background
- Resolution && level feature
 초반 layer에서는 높은 해상도를 갖고 있지만 각 pixel하나는 큰 의미가 없을 수 있다. (매우 작은 object면 있을 수도 있음. 하지만 대부분 object들은 거의 pixel 하나에만 들어있지 않고 across하기 때문에 그럴리는 적다.) FC를 제외하고 뒤로가면 갈수록 해상도는 낮아지지만 depth가 깊어지고 각 pixel에 담는 정보는 매우 의미있음을 알 수 있다.
여기서 pixel은 x.shape = (512, w, h)로 봤을때 x[:, p_x, p_y] 값을 의미한다. 또한 FC를 제외하고 생각하자.
초반 layer에서는 높은 해상도를 갖고 있지만 각 pixel하나는 큰 의미가 없을 수 있다. (매우 작은 object면 있을 수도 있음. 하지만 대부분 object들은 거의 pixel 하나에만 들어있지 않고 across하기 때문에 그럴리는 적다.) FC를 제외하고 뒤로가면 갈수록 해상도는 낮아지지만 depth가 깊어지고 각 pixel에 담는 정보는 매우 의미있음을 알 수 있다.
여기서 pixel은 x.shape = (512, w, h)로 봤을때 x[:, p_x, p_y] 값을 의미한다. 또한 FC를 제외하고 생각하자. - Scale
- Small Scale => 나무
- Large Scale => 숲

- 비교

- 그러면 객체를 인식하기 위해서는 Large Scale을 만드는 것이 좋을 것이다. 그러기 위한 방법으로는 2가지가 있다.
- Window Size를 늘린다. (맨 오른쪽 그림)
- Image Size를 줄인다. (3번째 그림)
- 그림에서는 window 크기를 늘린 것과 image 크기를 줄이는게 차이가 있어보이지만 사실은 차이가 없다. 의미만 부여하기 위해 만들었다.
- 그러면 객체를 인식하기 위해서는 Large Scale을 만드는 것이 좋을 것이다. 그러기 위한 방법으로는 2가지가 있다.
- Resolution && level feature
- Paper list

- Object Detection Milestones

- 이전에 object detection에는 one-stage detector와 two-stage dectector가 있다고 소개했습니다.
- 1-Stage Detector는 Region Proposal -> Classification이 순서대로 실��행
- 2-Stage Detector는 Region Proposal, Classification이 동시에 실행
FPN
 이 그림은 FPN을 검색하면 나오는 대표적인 그림이다. 이를 바탕으로 설명한다.
이 그림은 FPN을 검색하면 나오는 대표적인 그림이다. 이를 바탕으로 설명한다.
- Featurized image pyramid
 위 background에서 설명했던 내용처럼 Large Scale을 맞추기 위해서는 방법이 두 가지가 있다. 하나는 Window box를 늘리거나 또 하나는 Image size를 조정하는 것이다. Featurized image pyramid는 후자이다. 따라서 Image size를 변경해서 예측한다. 하지만 이는 자원소모가 크고 빠른 속도를 기대할 수 없다. 따라서 다른 방식이 나오기 시작한다. 해당 방법을 쓴 model은 Overfeat, HOG, SIFT 등이 있다.
위 background에서 설명했던 내용처럼 Large Scale을 맞추기 위해서는 방법이 두 가지가 있다. 하나는 Window box를 늘리거나 또 하나는 Image size를 조정하는 것이다. Featurized image pyramid는 후자이다. 따라서 Image size를 변경해서 예측한다. 하지만 이는 자원소모가 크고 빠른 속도를 기대할 수 없다. 따라서 다른 방식이 나오기 시작한다. 해당 방법을 쓴 model은 Overfeat, HOG, SIFT 등이 있다.

- Single feature map
하나의 image를 넣어서 사용하는 방법이다. 속도 측면에서는 좋지만 이전 방법보다는 정확도가 떨어진다는 단점이 있다. 가장 대표적으로 Yolov1이 있다.

- Pyramidal feature hierarchy
 "그러면 Large Scale을 적용하는 방법으로 Image 크기를 줄이는 법이 있는데 VGG같은 경우 일정 비율로 pooling 되니까 이를 stage마다 적용하는 방법이 있지 않을까?" 에서 시작했다고 생각한다. 가장 대표적인 모델은 SSD가 있다.
"그러면 Large Scale을 적용하는 방법으로 Image 크기를 줄이는 법이 있는데 VGG같은 경우 일정 비율로 pooling 되니까 이를 stage마다 적용하는 방법이 있지 않을까?" 에서 시작했다고 생각한다. 가장 대표적인 모델은 SSD가 있다.
 근데 아까 High Resolution이면 low feature를 갖는다고 했고 Low Resolution이면 high feature를 갖는다고 했다. forward 도중 predict를 진행하기에 cost 측면에서는 좋다. 하지만 높은 해상도에서는 좋은 feature들을 얻을 수 없다. 그렇기에 높은 해상도에서 관측 가능한 작은 객체들을 탐지하기 어려울 것이다.
그래서 여기서 하나 단어를 잡고 가면 Semantic Gap이다.
근데 아까 High Resolution이면 low feature를 갖는다고 했고 Low Resolution이면 high feature를 갖는다고 했다. forward 도중 predict를 진행하기에 cost 측면에서는 좋다. 하지만 높은 해상도에서는 좋은 feature들을 얻을 수 없다. 그렇기에 높은 해상도에서 관측 가능한 작은 객체들을 탐지하기 어려울 것이다.
그래서 여기서 하나 단어를 잡고 가면 Semantic Gap이다.

- Feature Pyramid Network
 그래서 나온게 FPN이다. 그러면 봐야하는 특징이 세 가지 있다.(Yolov3 모델로 설명할 것이다. 사실 완벽한 FPN은 아닌 것 같다.)
그래서 나온게 FPN이다. 그러면 봐야하는 특징이 세 가지 있다.(Yolov3 모델로 설명할 것이다. 사실 완벽한 FPN은 아닌 것 같다.)
- bottom-up pathway


 해당 부분은 downsampling 과정이고 해상도를 낮추면서 feature level을 높이는 단계이다. FNP 논문에서는 ResNet을 기준으로 설명했다.
해당 부분은 downsampling 과정이고 해상도를 낮추면서 feature level을 높이는 단계이다. FNP 논문에서는 ResNet을 기준으로 설명했다. - top-down pathway
해당 부분은 upsampling 과정이다. 해상도를 높이는데 feature를 갖고 간다. 방법은 nn.Upsampling 공식 문서를 확인해도 되지만 간략히 설명하면 neareast는 아래와 같은 방식으로 동작한다.

- lateral connections

 여기 부분이 yolov3와 다르다. FNP는 +를 한다. 하지만 yolov3는 depth기준 concat을 수행한다.
여기 부분이 yolov3와 다르다. FNP는 +를 한다. 하지만 yolov3는 depth기준 concat을 수행한다.
 해당 부분이 어떤 의미가 있는지는 좀 더 찾아보겠다.
본 논문에서는 아래와 같은 + 연산으로 1x1 conv에서 output 값을 맞춰준다. 따라서 같은 shape로 + 연산이 이루어진다.
해당 부분이 어떤 의미가 있는지는 좀 더 찾아보겠다.
본 논문에서는 아래와 같은 + 연산으로 1x1 conv에서 output 값을 맞춰준다. 따라서 같은 shape로 + 연산이 이루어진다.
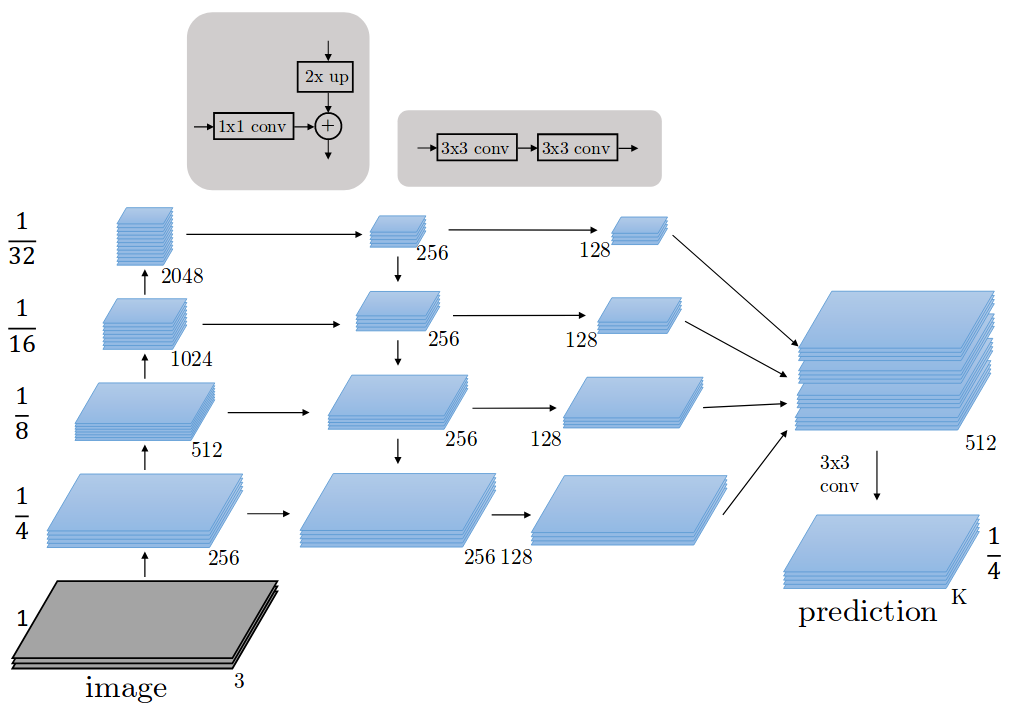
- bottom-up pathway
Region Proposal Network(RPN)
해당 내용은 Faster-RCNN에서 나온 내용이다. Yolov2에서 anchor는 위 논문을 보고 따왔다.
3.1 Region Proposal NetworksA Region Proposal Network (RPN) takes an image(of any size) as input and outputs a set of rectangularobject proposals, each with an objectness score.3 Wemodel this process with a fully convolutional network[7], which we describe in this section. Because our ultimate goal is to share computation with a Fast R-CNNobject detection network [2], we assume that both netsshare a common set of convolutional layers. In our experiments, we investigate the Zeiler and Fergus model[32] (ZF), which has 5 shareable convolutional layersand the Simonyan and Zisserman model [3] (VGG-16),which has 13 shareable convolutional layers.To generate region proposals, we slide a smallnetwork over the convolutional feature map outputby the last shared convolutional layer. This smallnetwork takes as input an n × n spatial window ofthe input convolutional feature map. Each slidingwindow is mapped to a lower-dimensional feature(256-d for ZF and 512-d for VGG, with ReLU [33]following). This feature is fed into two sibling fullyconnected layers—a box-regression layer (reg) and abox-classification layer (cls). We use n = 3 in thispaper, noting that the effective receptive field on theinput image is large (171 and 228 pixels for ZF andVGG, respectively). This mini-network is illustratedat a single position in Figure 3 (left). Note that because the mini-network operates in a sliding-windowfashion, the fully-connected layers are shared acrossall spatial locations. This architecture is naturally implemented with an n×n convolutional layer followedby two sibling 1 × 1 convolutional layers (for reg andcls, respectively).3.1.1 AnchorsAt each sliding-window location, we simultaneouslypredict multiple region proposals, where the numberof maximum possible proposals for each location isdenoted as k. So the reg layer has 4k outputs encodingthe coordinates of k boxes, and the cls layer outputs2k scores that estimate probability of object or notobject for each proposal4. The k proposals are parameterized relative to k reference boxes, which we callanchors. An anchor is centered at the sliding windowin question, and is associated with a scale and aspectratio (Figure 3, left). By default we use 3 scales and3 aspect ratios, yielding k = 9 anchors at each slidingposition. For a convolutional feature map of a sizeW × H (typically ∼2,400), there are W Hk anchors intotal.
fpn